
Vamos a explicar por pasos el sistema que tiene Smart Escrow para construir un sistema de scoring basado en un machine learning supervisado.
1. Queremos financiar Órdenes de Pedido de proveedores de grandes marcas
La banca tradicional financia de forma directa las facturas entre proveedores y sus clientes, pero para órdenes de pedido, que cronológicamente se sitúan en un paso anterior, no tiene un producto propio.
Gracias a los avances tecnológicos producidos en campos como la Inteligencia Artificial o el tratamiento de la Big Data y actuando en mercados que se rigen por EDI, alcanzamos la trazabilidad óptima que nos posibilita llegar al tejido empresarial primario, financiando de forma directa en una de sus primeras fases: las Órdenes de Pedido.

Esquema de Funcionamiento de Smart Escrow con respecto al financiador
2. Para ello necesitamos construir un sistema de scoring automatizado que clasifique a dichos proveedores
Para que nuestro proveedor pueda disponer de la financiación en cuanto una gran marca necesite de sus productos, tenemos que definir un sistema capaz de calcular con alta precisión el rating que determinará las condiciones de dicha financiación, sin dilaciones que puedan perjudicar la posibilidad de crecimiento en su negocio (que a su vez se traduce en un producto de mayor calidad y más competitivo para las grandes superficies). Es decir, necesitamos de un entorno que automatice tanto el análisis de la información como el cálculo del rating (devolviendo un scoring), de forma que se optimiza la detención de posibles escenarios de riesgo y se pone a disposición del proveedor la financiación acortando al máximo los tiempos de espera y sin trámites tediosos.
Desde el momento en que una gran marca comunica a su proveedor un pedido hasta que se paga la factura correspondiente, se generan una serie de archivos EDI (ORDERS, DESADV, RECADV, INVOIC, etc.) que determinan una serie de hitos en la consecución de la operación y que contienen información que caracteriza de forma única a esa operación concreta. Analizar un único pedido para poder extraer conclusiones que deriven en predecir posibles escenarios de riesgo (rating de un proveedor) no aportaría mucho, necesitamos estudiar de forma simultánea la plenitud de la información a través del histórico de pedidos. ¿Cuánto tiempo tardaría una persona en analizar y extraer la información relevante de 500 operaciones?
Imaginad ahora la inmensa cantidad de datos que generan todo el conjunto de grandes marcas de un sector y la diversidad de sus proveedores. Ahí están las tendencias de los grandes mercados, una información que no podemos obviar si queremos realmente hacer un análisis minucioso y relevante de los riesgos. Hasta hace unos años los sistemas tradicionales de rating eran una buena opción, pero con el desarrollo tecnológico en cuanto al tratamiento de la Big Data, podemos procesar todo este volumen ingente de información que nos ayudará a ser más precisos y a anticipar el riesgo mucho antes que los análisis clásicos. La automatización en el proceso es tan necesaria como posible.
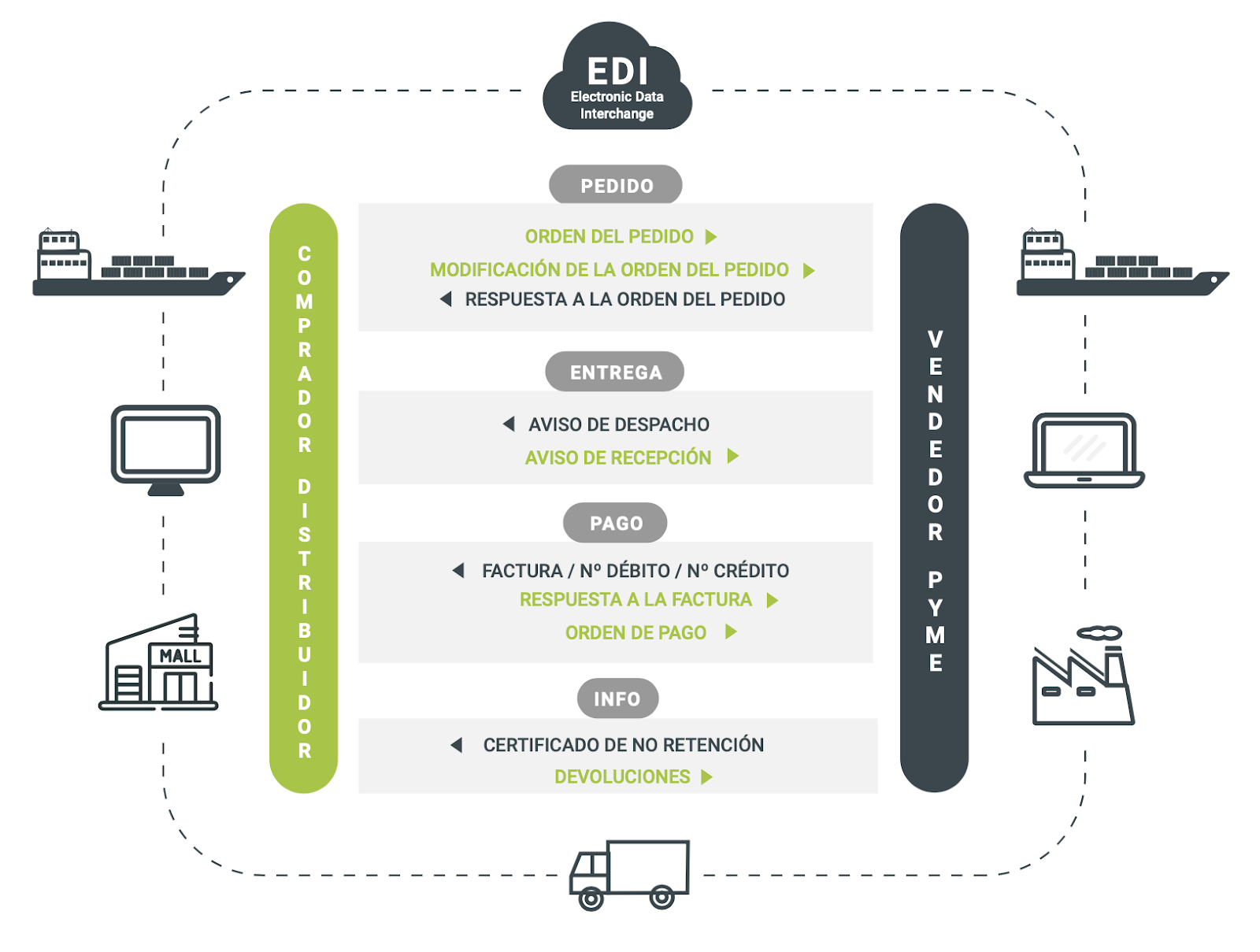
Funcionamiento del Sistema EDI entre proveedor-cliente
3. Queremos construir este sistema de scoring usando un modelo de Machine Learning Supervisado
Y es que no sólo el desarrollo tecnológico se quedó en el tratamiento de grandes bases de datos, sino que va mucho más allá, como por ejemplo en el campo de la Inteligencia Artificial.
En nuestro caso, el desarrollo de Machine Learning, una rama de la Inteligencia Artificial que crea sistemas de aprendizaje automáticos basados en la identificación de patrones complejos entre millones de datos para predecir comportamientos futuros va a ser una piedra angular para desarrollar este proyecto. Entre la gran cantidad de información que podemos captar de todos los archivos EDI entre un proveedor y su cliente y en las bases de datos correspondientes a las tendencias de los grandes mercados, vamos a definir un algoritmo capaz de analizar la totalidad de los datos (variables y premisas) y encontrar la correlación entre estos y los sucesos “el proveedor se retrasará en la devolución de la financiación” y/o “el proveedor no devolverá la financiación”, devolviendo un scoring de riesgo dinámico, que variará en cada nueva operación, fijando las condiciones para financiar la misma.
Aunando el desarrollo tecnológico en varios campos, automatizamos un proceso de forma que podemos ofrecer un producto, la financiación directa de órdenes de pedido de proveedores de grandes marcas, que llegará antes y cubrirá mejor las necesidades del proveedor, minimizando y anticipando el riesgo más que con los sistemas tradicionales.

Esquema del funcionamiento de nuestro sistema scoring
4. Con el objetivo de predecir los escenarios “El proveedor se retrasará en la devolución de la financiación” y/o “El proveedor no devolverá la financiación”:
Identificamos estos dos eventos como el fracaso en una operación de financiación. Son inequívocamente los escenarios que queremos anticipar con la suficiente antelación para que nunca puedan darse. Desde el primer momento, nuestro sistema enfoca el análisis en encontrar patrones de correlación entre una inmensidad de datos (información) con estos dos sucesos. Siempre de forma proactiva, sin esperar a que estos resultados negativos se plasmen en balances o cuentas trimestrales.
Para ello, queremos mostrar nuestra forma de actuación con los proveedores, explicando paso a paso y de forma esquematizada cómo sería la relación Proveedor — Smart Scrow.
4.1 Determinar cuáles son los proveedores que cumplen con los requisitos para optar a nuestra financiación
Como requisito previo, antes de formalizar la colaboración con un proveedor, se verificará una serie de documentación básica con la finalidad de determinar que el proveedor tiene un acuerdo para abastecer a una gran marca y no es deudor de instituciones como Hacienda o la Seguridad Social. Será el único instante no automatizado del proceso. Una vez que se ha verificado este punto, no habrá más trámites tediosos y el proveedor dispondrá de forma automática de las financiaciones que se generen con cada nueva Orden de Pedido en su cuenta Scrow.
4.2 el % de interés de la primera operación
Que será determinado en base a un Pre-Scoring inicial basado en las comunicaciones EDI previas entre el proveedor y su cliente, ya que nuestro sistema tendrá acceso a las mismas sin necesidad de que el proveedor tenga que aportarlas (EDI almacena de forma gratuita los archivos generados en las relaciones comerciales durante 3 meses) y a las propias características de la primera Orden de Pedido que será financiada con nosotros. Nuestra Machine Learning tendrá la información necesaria para fijar ya las condiciones de esta primera financiación.
4.3 y de las siguientes operaciones de cada proveedor
Y de forma dinámica, este scoring irá variando conforme nos lleguen las nuevas Órdenes de Pedido del proveedor, fijando para cada una de ellas unas condiciones propias en base a una puntuación que representará los posibles escenarios de riesgo en cuanto a los dos sucesos definidos con anterioridad.
4.4 generar un sistema de alertas que permita avisar de que un proveedor podría dejar de cumplir los requisitos
Además generará un sistema de alertas y advertencias cuando se den ciertos patrones identificados con posibles escenarios de riesgo que permitirán, en función de la gravedad, ciertas acciones como la obligatoriedad de destinar la cantidad de dinero financiada a un fin único (por ejemplo, comprar materias primas necesarias para la fabricación del pedido) e incluso la congelación de la cuenta scrow o la paralización de la financiación. Gracias a la trazabilidad que tenemos vía EDI de los hitos en la consecución de la relación comercial proveedor — cliente y a la premura en analizar de forma automática el conjunto de la información relevante podemos anticiparnos.
5. Para ello disponemos de dos tipos de Variables:
Nuestro sistema de Scoring automatizado basado en la creación de un entorno de Machine Learning se apoya en dos pilares fundamentales: la información estructurada que nos aportan los archivos EDI generados a través de un pedido de un proveedor y su cliente y de las grandes bases de datos correspondientes a los hábitos de compras de las grandes superficies y los usuarios de las mismas. Cuando procesamos dicha información, se produce un estado declarativo e identificativo de esos datos con variables que el sistema va a reconocer como las causantes de que la operación llegue a buen término o por el contrario puedan surgir ciertas complicaciones. Dividimos estas variables según la naturaleza y fuente de procedencia:
5.1 Endógenas, es decir internas a la propia relación proveedor-gran distribuidor, y cuya fuente es el EDI (mapa de variables)
Son aquellas variables que podemos extraer de un archivo EDI. Si imaginamos por ejemplo un archivo ORDERS al uso, sabemos que vamos a poder identificar el número de pedido, el proveedor, comprador, qué productos se piden y en qué cantidades, cuándo se debe entregar ese pedido, el importe unitario del producto, el importe total del pedido, el descuento global o descuento por línea de producto, etc. Si por ejemplo tenemos ahora en cuenta el archivo RECADV correspondiente al mismo pedido sabremos si el pedido llegó a tiempo o se retrasó en el envío, si llegaron todas las unidades pedidas de un producto o no, si se ha cancelado parte de ese pedido por llegar la mercancía dañada, si la mercancía que llegó no tenía el suficiente margen en la fecha de caducidad, etc.
Toda esta información la vamos a asignar a variables que identificamos como endógenas, interna a la propia relación comercial entre un proveedor y su cliente.

Ficheros EDI más importantes y variables que capturamos
5.2 Exógenas, es decir externas a la propia relación proveedor-gran distribuidor, y cuya fuente es el Mercado, C.Compras, etc… (mapa de variables)
Pero a su vez, si realmente queremos estar en disposición de conseguir un scoring lo suficientemente acertado y representativo del riesgo que representa una operación, no podemos obviar en ningún caso las tendencias de los grandes mercados. Esa información nos va a ayudar a discernir y a entender los datos en bruto que se presentan en un archivo ORDERS.
Imaginad que gracias a las bases de datos de compras de las grandes superficies de los últimos 20 años, sabemos que en el mes de abril siempre las compras de un bien cualquiera se incrementan en media un 30%. Si estamos en ese periodo y vemos que nuestro proveedor ha intensificado el suministro de ese producto en un 10% a su cliente… Podremos concluir que no es un buen dato, que realmente se está produciendo un decrecimiento de negocio. Sin embargo, si hubiésemos pasado por alto dicha circunstancia, habríamos pensado que el proveedor está aumentando sus ventas.
Son variables exógenas, es decir, externas a la relación particular de un proveedor con su cliente, todas aquellas que marcan las tendencias y evolución de los grandes mercados y los hábitos de consumo.
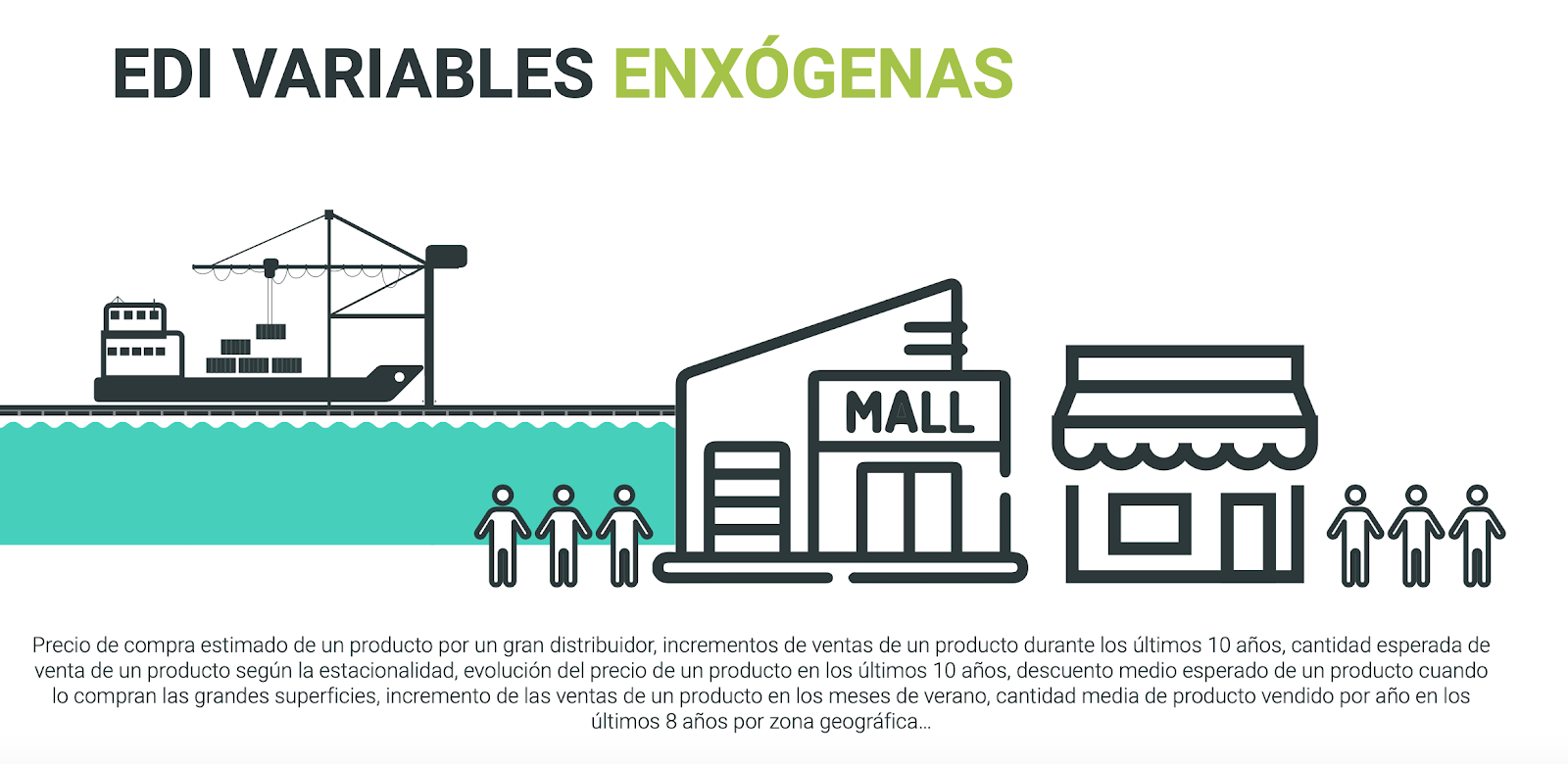
BBDD Externas que nos sirven para ajustar los datos
6. Estas Variables cuentan siempre con dos dimensiones temporales:
Parece evidente por la propia naturaleza de las variables que no podemos entender su significado pleno sin tener en cuenta su ámbito temporal. Atendiendo a este factor, definimos dos conjuntos:
6.1 Históricas (p.e. últimos 6 meses de EDI) — necesarias para los objetivos 4.1 y 4.2
Cuando necesitamos tener en cuenta la evolución, la tendencia, la variación de un valor en el transcurso del tiempo. Serían de esta naturaleza temporal por ejemplo la cantidad de veces que se ha retrasado en la entrega de las mercancías un proveedor respecto al total de envíos que ha hecho, con qué frecuencia ha sufrido cancelaciones de pedidos un proveedor en el conjunto de sus operaciones de los dos últimos años, cuántas veces el proveedor no alcanza la media de incremento en la venta de un producto en los meses estivales (si por ejemplo sabemos que durante ese verano se incrementa la venta de ese producto en los mercados), etc. De ahí, que las definamos como históricas. Para entender su magnitud hay que analizarlas durante el transcurso del tiempo, con la totalidad de los pedidos o los pedidos efectuados durante un periodo concreto.
6.2 Dinámicas (p.e. el EDI de la operación en curso) — necesarias para los objetivos 4.3) y 4.4)
Son aquellas que expresan información plena en el momento actual y que determinan las características que hacen únicas a cada pedido. Por ejemplo qué producto pide una gran marca a su proveedor en este pedido. Cuántas unidades demanda de dicho producto, etc.

Esquema de un ejemplo de funcionamiento de variables en tiempo real e históricas
7. Bases de Datos Portuarias: mayor número de variables endógenas y exógenas.

3 Puntos importantes que nos da la información de los puertos
Parece lógico pensar que nuestro sistema de scoring funciona de forma más precisa y es capaz de determinar mejor y con mayor antelación un posible escenario de riesgo conforme analiza más operaciones y dispone de más bases de datos para captar tendencias y relacionar patrones.
De ahí que pensemos que sería una aportación inmensa para el proyecto contar con los datos que pueden proporcionar los puertos respecto al flujo de mercancías por vía marítima, siendo sin duda un gran paso que nos va a permitir conseguir un sistema más fortalecido y ágil que una el mundo financiero y logístico y que abre las puertas para incrementar el negocio, ya que se estaría financiando a las pymes de forma directa en sus primeros pasos de producción.